はじめに
何らかのデバイスやウェブなどでデータを取得したとします。これをアップロードすると、自動的に機械学習や統計などで動的に解析が行われ、その解析結果を視覚的にわかりやすくヴィジュアライズに出力するwebアプリケーションの作成を考えます。この時、ブラウザからアップロードされたCSVファイルをどのようにpythonの変数に渡すかが一つの課題となります。本ページでは、この解決方法について説明しています。
CSVデータの用意
まず、エクセルなどを開き、データを入力します。
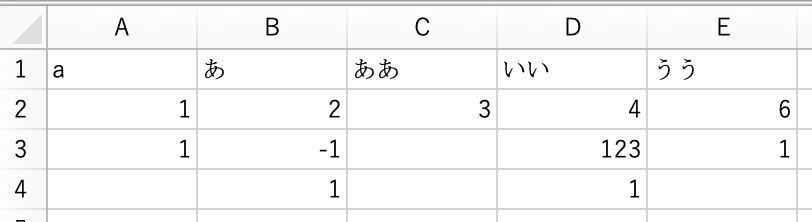
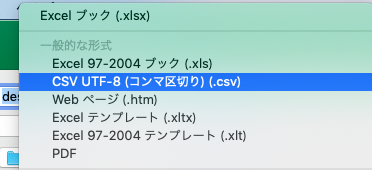
次に、保存を行いますが、この手続きは結構重要です。Macでcsvファイルを作るとき、UTF-8と明示されているCSVファイル形式と、何も記載されていないCSVファイル形式による保存が選択できます。前者はutf-8で保存され、後者の場合はsift-jisで保存されます。混乱しないようにしてください。sift-jisは日本でしか通用しない文字コードなので、utf-8で保存しましょう。すなわち、画像の選択肢を選んで保存します。
コード
atomで新規ファイルを作成し、以下のコードをコピペで貼り付け、ターミナル上で「python3 xxx.py」と打ち、サーバを起動させてください。その後、ブラウザでlocalhost:9999と打ちこみ、ページを表示させてください。その後、csvファイルを選択し、ボタンを押すと、その中身がpythonの変数(rawdat)に代入され、表示されます。なお、巨大なファイルの扱いを避けるために、rawdatの長さを測定し、Limit以上であれば解析しないようにしています。
# -*- coding: utf-8 -*-
from bottle import route, run, get, post, request, debug
# CSVファイルをアップロードするページ
@get('/')
def InputFile():
t= '''
'''
return t
# ファイルの中身を解析するページ
@post('/SavePage')
def SaveFile():
getdat = request.files.csvdat
rawdat = getdat.file.read()
FileSize = len(rawdat)
Limit = 5000 #サイズ上限
if FileSize >= Limit:
return "ファイルサイズが大きすぎるため処理を行いません!(" + str(FileSize) + "bytes)"
elif FileSize < Limit:
# 処理を実行!
return "処理を終了しました。(" + str(FileSize) + "bytes)ファイルの中身: " + str(rawdat) else: return "ファイルサイズが不明なので、処理を行いません。" # サーバの起動(一番下に書くこと) run(reloader=True, port=9999)
ポイントは8行目のcsvdat(HTML)です。ここで、HTMLにて定義づけられたcsvdatに対して、CSVデータが保持されます。その後、20行目でpythonの変数であるgetdatにこの情報が渡され、21行目でpythonの変数であるrawdatにCSVファイルの中身がbytes型で渡されます。
bytes型への対応
なお、「getdat = request.files.csvdat, rawdat = getdat.file.read()」にてCSVファイルの中身をrawdatに代入していますが、rawdatはpythonにおけるbytes型と呼ばれる型の変数となっています。これは、全角文字を16進数で表示されているので、もしかすると直感的に扱うにくいかもしれません。これを解決するために、bytes型をstr型に変換します。
まずは、扱うCSVファイルの文字コードを知ることが必要です。ターミナルで以下のコマンドを打ち込むことで、文字コードを調べることができます。
nkf -guess xxx.csv
すると、おそらく多くの場合「shift-jis」か「utf-8」が返ってくると思います。これをpythonのコード上でbytes型をstr型にキャストするには、以下のように記述します。
rawdat_dec = rawdat.decode('shift_jis')
rawdat_dec = rawdat.decode('UTF-8')
どちらか一方が正解です。ただし、きちんとnkfで確認した文字コードを指定しないと、エラーになるので注意が必要です。とはいえ、ユーザがどちらを使用するのかは未知数です。こういった場合は、以下のように記述するといいです。
from bottle import route, run, get, post, request, debug
# CSVファイルをアップロードするページ
@get('/')
def InputFile():
t= '''
'''
return t
# ファイルの中身を解析するページ
@post('/SavePage')
def SaveFile():
getdat = request.files.csvdat
rawdat = getdat.file.read()
FileSize = len(rawdat)
Limit = 5000 #サイズ上限
try:
Dec_rawdat = rawdat.decode("shift_jis")
except:
Dec_rawdat = rawdat.decode("UTF-8")
if FileSize >= Limit:
return "ファイルサイズが大きすぎるため処理を行いません!(" + str(FileSize) + "bytes)"
elif FileSize < Limit:
# 処理を実行!
return "処理を終了しました。(" + str(FileSize) + "bytes)ファイルの中身: " + Dec_rawdat else: return "ファイルサイズが不明なので、処理を行いません。" # サーバの起動(一番下に書くこと) run(reloader=True, port=9999)
ポイントは24〜27行目です。はじめにsift_jisへのデコードを試みて、それがダメだったらutf-8へのデコードを試みます。
データの取り出し
前述のコードにより、Dec_rawdatに対し、CSVファイルの中身を書き出すことができました。CSVファイルの1セルのデータを1つ1つ分割して保存しなければ、解析などの利用できません。このためには、大きく分けて以下3つの手続きが必要です。
- ゴミを除去する。
- 改行コードでデータを分割することで、行成分のデータを取り出す。
- カンマ(,)でデータを分割することで、列成分のデータを取り出す。
ここでいうゴミの除去とは、人間の目には見えない改行を表すコードなどです。これを消さないと、データの中に、改行コードなどが混ざってしまうので、計算などができなくなってしまいます。
次に、長い文字列のデータを、改行を発見し、1行1行分割されたデータに変換します。最後に、そのデータをカンマで区切ることで、CSVファイルのセル1つ1つが分割されたデータを入手します。
これを実現するコードは以下の通りです。上のコードで、Dec_rawdatを生成した後に入れてください。
# ゴミの除去
Dec_rawdat = Dec_rawdat.replace("\ufeff","") # テキスト開始コード
Dec_rawdat = Dec_rawdat.replace("\r","") # 改行コード
# 改行でデータ区切りし、リストへ
LineDat = Dec_rawdat.split(os.linesep)
# カンマでデータ区切り
CSVdat = []
for i in range(0,len(LineDat)):
CSVdat.append(LineDat[i].split(","))
# データ表示
print(CSVdat)
はじめに、replace関数で、ゴミとなる文字コード(\ufeff, \r)を、何もない文字に変換します。その後、split関数で、改行を意味するlinesep区切りで、データを分割し、リストに格納します。最後に、split関数でカンマ区切りのデータを取得します。この手続きで、変数CSVdatに対し、1セル1セルが分割されたデータを取得することができます。