0. はじめに: どうしてもうまくできない人へ¶
本実験では、プログラミングによって、人工知能を構築する練習を行います。ただ、どうしてもパソコンやプログラミングを受け付けないという方もいると思います。このページの説明を見て、自分なりに努力しても、どうしてもうまくいかない人は、以下に示す代替の課題に取り組んでください。
1. Google Colaboratory の設定¶
本授業では、プログラミング言語pythonを使用します。これは、機械学習、人工知能、統計学といったデータ分析をはじめ、webアプリケーション開発、組込みシステム開発、といったシステム開発まで、とにかくなんでもできる万能なプログラミング言語です。この勉強のために、Google Colaboratory というオンラインプログラミングを実施します。
手続き: 1
Google Colaboratoryは、Webブラウザで実行できるプログラミング環境です。ただ、あらゆるWebブラウザに対応しているわけではありません。Internet ExplorerやMicrosoft Edge では動きませんので、自分のパソコンに、Google Chromeをインストールします。Webブラウザから「Google Chrome インストール」で検索し、インストールしてください。

手続き: 2
Webブラウザ「Google Chrome」を開き、下記のページに飛んでください。Web検索で「Google Colab」と入力しても、行くことができます。
ここに行くと、下の画像のように、右上にログインボタンがあるので、そこを押し、自分の大学のアカウントでログインしてください。Gmailアカウントであればなんでもいいので、自分で取得しているフリーのGmailアカウントでもokです。
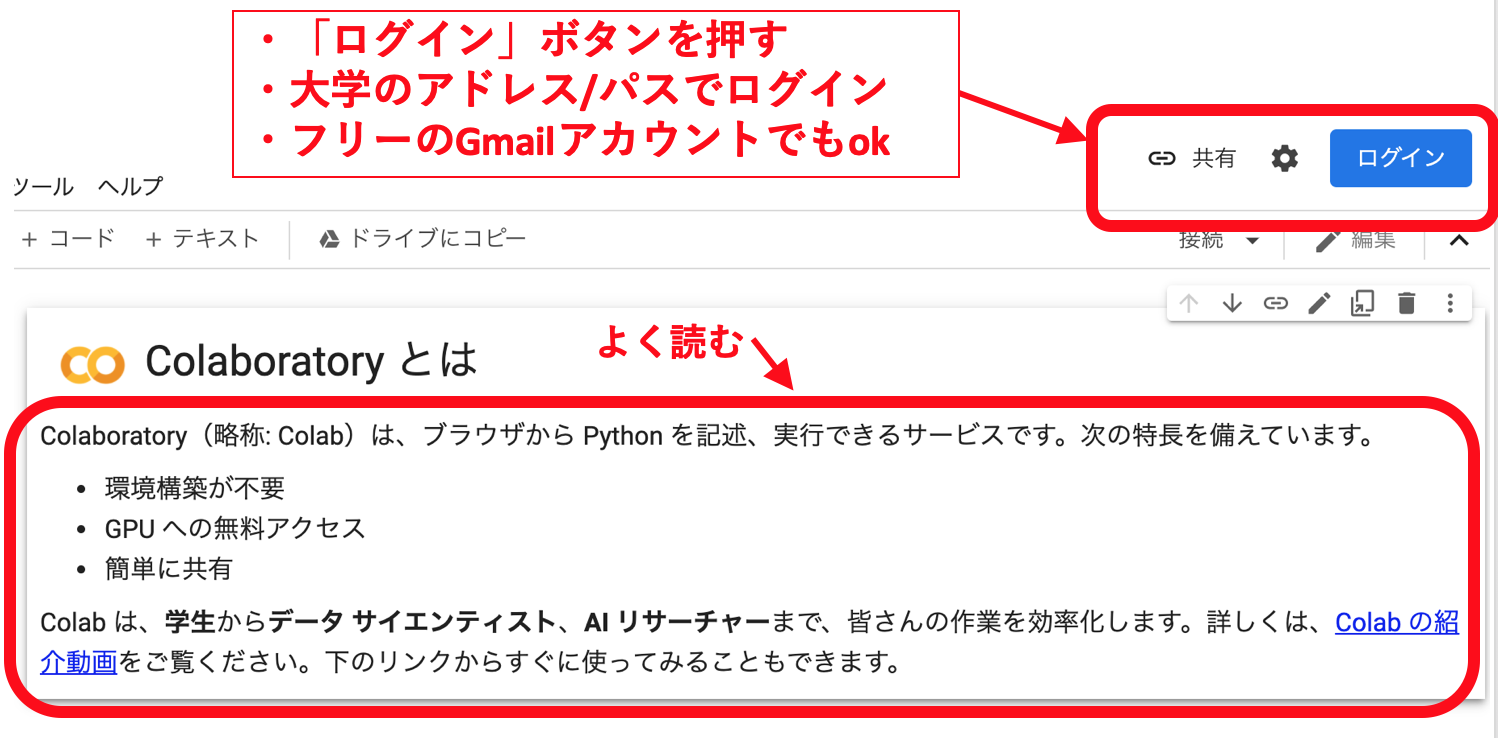
手続き: 3
続いて、下の画像のように各セルをクリックし、ゴミ箱マークを出現させ、それを押します。これにより、初めから記載されている説明文をすべて削除していきます。
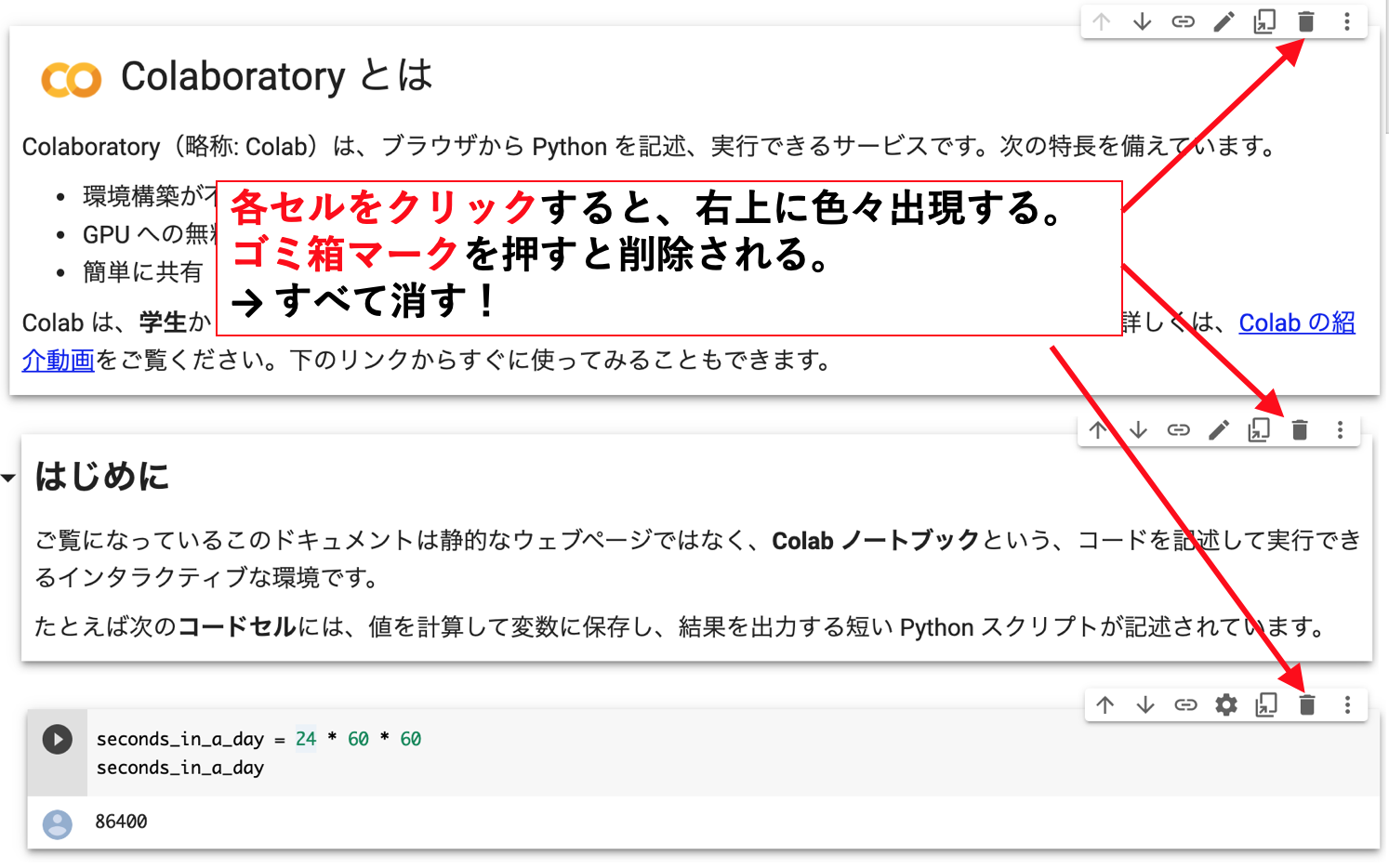
下のように、まっさらになればokです。
手続き: 4
その後「+コード」ボタンを押します。すると、プログラムの入力欄が用意されます。
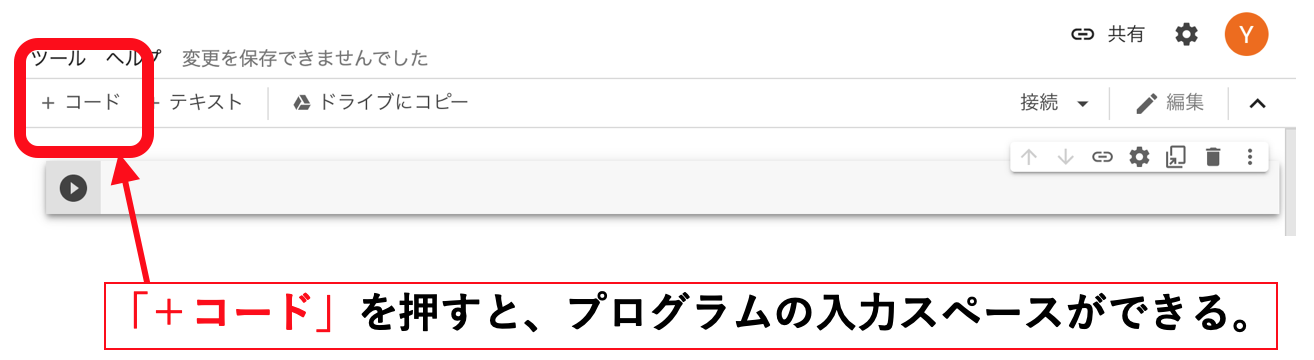
試しに、以下のコードをコピペし、貼り付けて、「再生ボタン」を押してください。
r = 10
menseki = r * r * 3.14
print("半径が", r, "の円の面積は", menseki, "です。")
上記コードは、以下の意味を持ちます。
- 1行目: 変数 r に、10を代入
- 2行目: 変数 menseki に「r r 3.14」を代入
- 3行目: 変数 r と menseki を表示
rは10ですから、10かける10かける3.14、つまり314がmensekiに代入されます。rとmensekiを表示すると、10と314が表示されることになります。
手続き: 5
続いて、もう一度「+コード」ボタンを押します。すると、2つ目のプログラムの入力欄が用意されます。今後、コードを記入していくときは、前のコードを消さずに、+コードボタンで新たな入力欄を用意して、そこに書き込むようにしてください。
2つ目の入力欄に、以下のコードをコピペしてみましょう。
a = 3
b = 5
c = a + b
print("c=", c)
8が表示されるかと思いきや、エラーが出ました。この理由は、全角スペースは含まれているためです。その位置は、
- print("c=", c)
となります。「,」の後ろに全角スペースがあるわけです。このように、プログラミングでは、全角文字は使用してはいけません。注意しましょう。正しくは、
a = 3
b = 5
c = a + b
print("c=", c)
となります。
さて、このままプログラミングの基礎に関する学習を進めたいところですが、本授業は、プログラミングの基礎は学習しません。あくまで、人工知能を実装する、体験学習です。したがって、プログラミングの基礎はここまでにしておきます。
###########
pythonプログラミングの勉強をしたい方:
注意: これは、授業とは関係ありません。やりたい方は、自主的にやるといいです、というお話です。
###########
2. 決定木とは¶
データマイニングは、多数存在するデータから自動的に知識を発見するための分析手法となります。この分析手法の一つに、決定木分析と呼ばれるものがあります。これは、データを与えることで、If-Then節(もし〜、ならば〜)形式の人間が解釈しやすいルールを抽出する機能を持ちます。ニューラルネットワークと同様に、数学的な基盤に基づくものですが、今回は体験してみようということなので、その説明はせず、こちらが与えた課題で使ってみる、ということをします。
2.1 教師データ¶
前提条件¶
今回の実験では、どのようなスマートフォンが売れるのか、その条件をデータマイニングによって抽出することを目標とします。このためには、スマホの属性を数値として表現します。そして、その数値がどのような状態のとき、売れるのか、売れないのかを明らかにしていきます。スマホの属性というと、非常に色々な種類がありますが、今回は授業の題材で取り扱うだけですので、シンプルに考えてみます。
- 入力情報(スマートフォンの属性):
- X0: サイズ(0: 小さい 〜 1: 大きい)
- X1: 価格(0: 安い 〜 1: 高い)
- X2: デザイン性(0: 悪い 〜 1: 良い)
- 出力情報(売行き):
- Y = C1: 売れる
- Y = C2: 売れない
つまり、サイズ、価格、デザイン性の3要素がどのような条件を満たしたとき、売れるのか、売れないのか、このルールを抽出していくわけです。
さて、これを実現するには、データが必要です。ニューラルネットワークと同様に、教師データがなければ何も始まりません。今回、以下に示す色々なスマートフォンを10個用意してみました。そしてそれが、売れるのか売れないのか、調べてみた結果を示します。
# X0: サイズ
X0 = [0.7, 0.6, 0.3, 0.2, 0.7, 0.8, 0.9, 0.8, 0.7, 0.6 ]
# X1: 価格
X1 = [0.4, 0.2, 0.6, 0.8, 0.7, 0.9, 0.8, 0.6, 0.7, 1.0 ]
# X2: デザイン性
X2 = [0.1, 0.9, 0.8, 0.1, 0.8, 0.9, 0.9, 0.2, 0.3, 0.1 ]
# Y: 売れ行き
C1 = "C1: 売れる"
C2 = "C2: 売れない"
Y = [C1, C1, C1, C1, C1, C1, C2, C2, C2, C2]
print("### 教師データ ###")
print("")
for i in range(0, len(Y)):
print(" ***", str(i), "番目の観測 ***")
print(" X0: サイズ = ", X0[i], " / X1: 価格 = ", X1[i],
" / X2: デザイン性 = ", X2[i], " ならば Y = ", Y[i])
print("")
課題1: 10個分のスマートフォンの、サイズ、価格、デザイン性、売れ行きをすべて記入してください。また、これを見て、どのようなスマホが売れそうか、売れなさそうか、自由に考察してください。
2.2 決定木の実装¶
それでは、これを実際に観測されたデータとみなし、決定木によるデータマイニングを行ってみます。これを実施するのが以下のコードとなります。1行目のYour_seed、学籍番号が偶数の人は0、奇数の人は1としてください。
Your_seed = 2 # ← 学籍番号が偶数の人は0、奇数の人は1とする。
from sklearn import tree
import numpy as np
# データ整形
X = np.zeros([len(Y), 3])
for i in range(0, len(Y)):
X[i, 0] = X0[i]
X[i, 1] = X1[i]
X[i, 2] = X2[i]
# 決定木の学習
TreeModel = tree.DecisionTreeClassifier(criterion='entropy', min_samples_leaf=2,
random_state=Your_seed)
TreeModel = TreeModel.fit(X, Y)
# 得られたモデルの可視化
import pydotplus
dot_data = 'Tree.dot'
tree.export_graphviz(TreeModel, out_file=dot_data) # モデル入力
graph = pydotplus.graphviz.graph_from_dot_file(dot_data)
graph.write_png('Tree.png') # pngで保存
graph.write_pdf('Tree.pdf') # pdfで保存
# jupyterで表示
print("*** 参考 ***")
print("X0サイズ(0小さい〜1大きい)")
print("X1価格(0安い〜1高い)")
print("X2デザイン性(0悪い〜1良い)")
print("value: 売れる数、売れない数")
from IPython.display import Image
Image(graph.create_png())

実行すると、よくわからない図が出てくると思います。これをわかりやすく書き換えるのが、次の課題となります。プログラムが出力する図の見方を示しますので、それを参考にしながら実施してください。なお、説明用の図はプログラムが出力する図とは違いますので、写しても正解になりません。
課題2: プログラムが出力する決定木を、わかりやすく変換してください。
- 手書きで記載し写真で撮る
- パワーポイントで図を作成する
いずれかの方法で作成し、レポート用紙に記載してください。
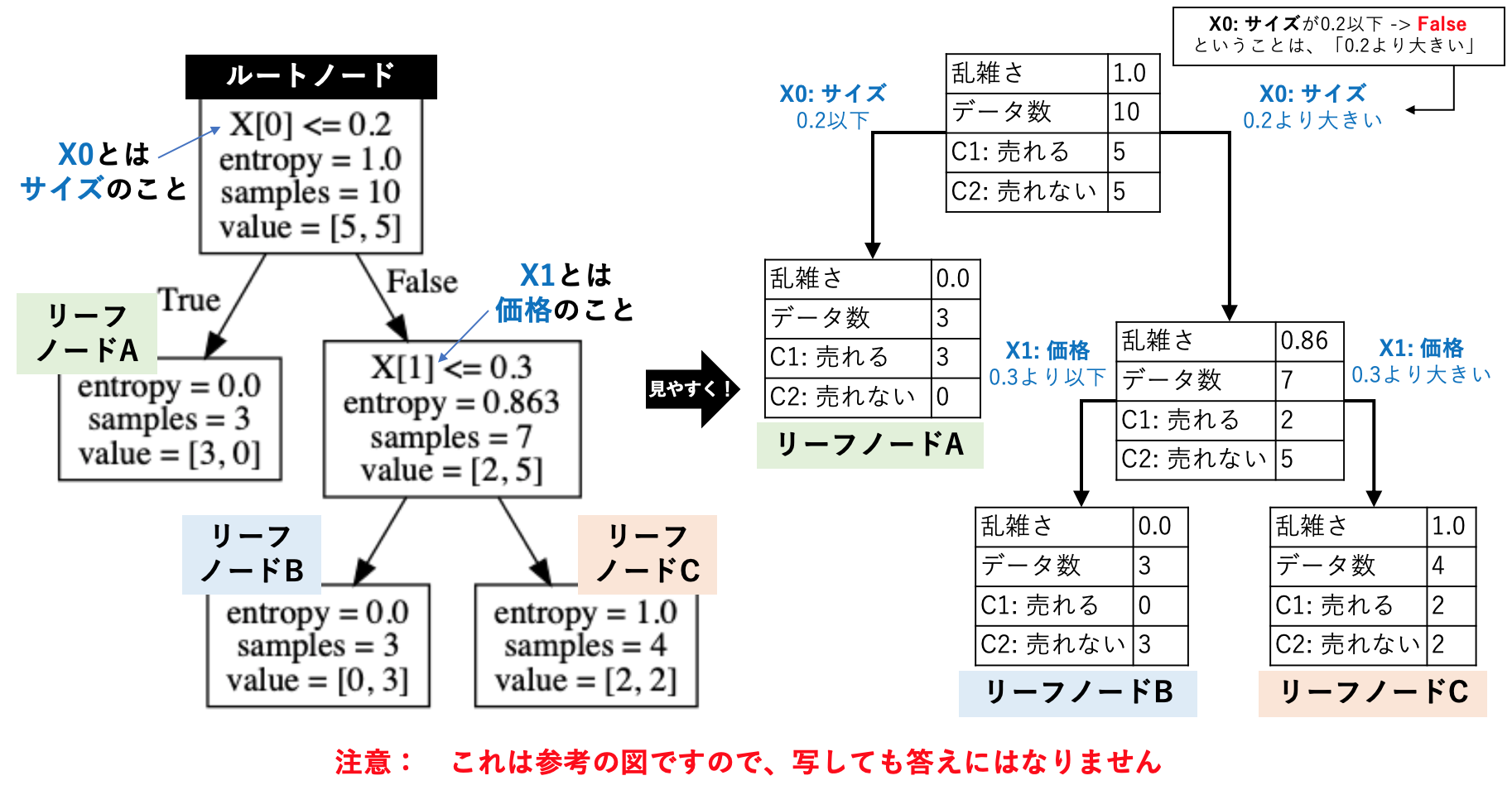 備考: 乱雑さ(エントロピー)とは、「売れる」「売れない」の混ざり具合です。完全に半分半分の場合は、乱雑さが1となり、完全にどちらか一方に偏った場合は、乱雑さが0となります。決定木とは、乱雑さを減少させるようなルールを自動発見するアルゴリズムとみなすことができます。決定木の数学的な基盤に興味がある人は、ID3アルゴリズムを調べてみましょう。
備考: 乱雑さ(エントロピー)とは、「売れる」「売れない」の混ざり具合です。完全に半分半分の場合は、乱雑さが1となり、完全にどちらか一方に偏った場合は、乱雑さが0となります。決定木とは、乱雑さを減少させるようなルールを自動発見するアルゴリズムとみなすことができます。決定木の数学的な基盤に興味がある人は、ID3アルゴリズムを調べてみましょう。
課題3: 決定木分析では、ルートノード、リーフノードと呼ばれる用語が登場します。この意味を説明してください。
課題4: 決定木分析では、リーフノードを日本語に翻訳することができます。今回抽出されたリーフノードを、日本語に翻訳してください。左から順に、リーフノードA, B, C, Dとします。
なお、課題2の説明用の図で示したリーフノードを翻訳すると、以下のようになります。参考にしてみてください。以下を写しても答えになりませんから、注意しましょう。

さて、ここまで実施すると、決定木分析は、データを集めると、ルールを取り出してくれる分析手法となることが、なんとなくわかってきたと思います。これはとても重要ですが、この分析手法のもう一つの利点として、予測が行える、というものがあります。これについて理解するために、以下の問題を解いてみましょう。
課題5: 得られた決定木を用いて、自分が独自に考えた「X0: サイズ」、「X1: 価格」、「X2: デザイン性」を5組考えて、そのスマホの売れ行きを予測してください。X0, X1, X2は0〜1の範囲で指定してください。
このように、決定木によって提案するスマホに対する売れ行きを予測できることがわかりました。人間がわかりやすいルールによって予測ができる、というのが決定木分析の利点です。これは大変便利なので、様々な場所で決定木分析が実施されています。これについて知るために、以下の課題を解いて、この実験を終わりとします。
課題6: 決定木分析はとても重要な分析手法と言われています。どうして重要だと言われるのか、今回の実験を通して思った、あなたの感想を記載してください。
課題7: 以下の論文の中から1つ選択肢し、下記の問題に取り組んでください。
文献リスト:
- [1] 携帯電話から入力された検索語句のマーケティング戦略への活用に関する提案(図表7), https://www.jstage.jst.go.jp/article/jasmin/2011f/0/2011f_0_98/_pdf/-char/ja
- [2] ファストファッションの消費行動を規定する要因(Fig.2), https://www.jstage.jst.go.jp/article/senshoshi/61/4/61_299/_pdf
- [3] 未払い履歴パターンの分析による貸倒債権の事前発見(図9), https://www.jstage.jst.go.jp/article/jasmin/2005s/0/2005s_0_74/_pdf/-char/ja
問題:
- (1) どの文献を選択したか、1つ記載してください。
- (2) 何を入力すると、何を出力してくれる決定木でしょうか?
- (3) その決定木は、どのような場面で、どう活用できるでしょうか。
備考: [1]は図表7、[2]はFig.2、[3]は図9を見て、本文を読みながら、それを解読してください。